Research data management (RDM) along with the FAIR principles of Findability, Accessibility, Interoperability and Reusability, allows for the verification, reproducibility and digital preservation of findings; fundamental to high quality research outputs and research integrity.
MTU (2025). Research Integrity Policy.
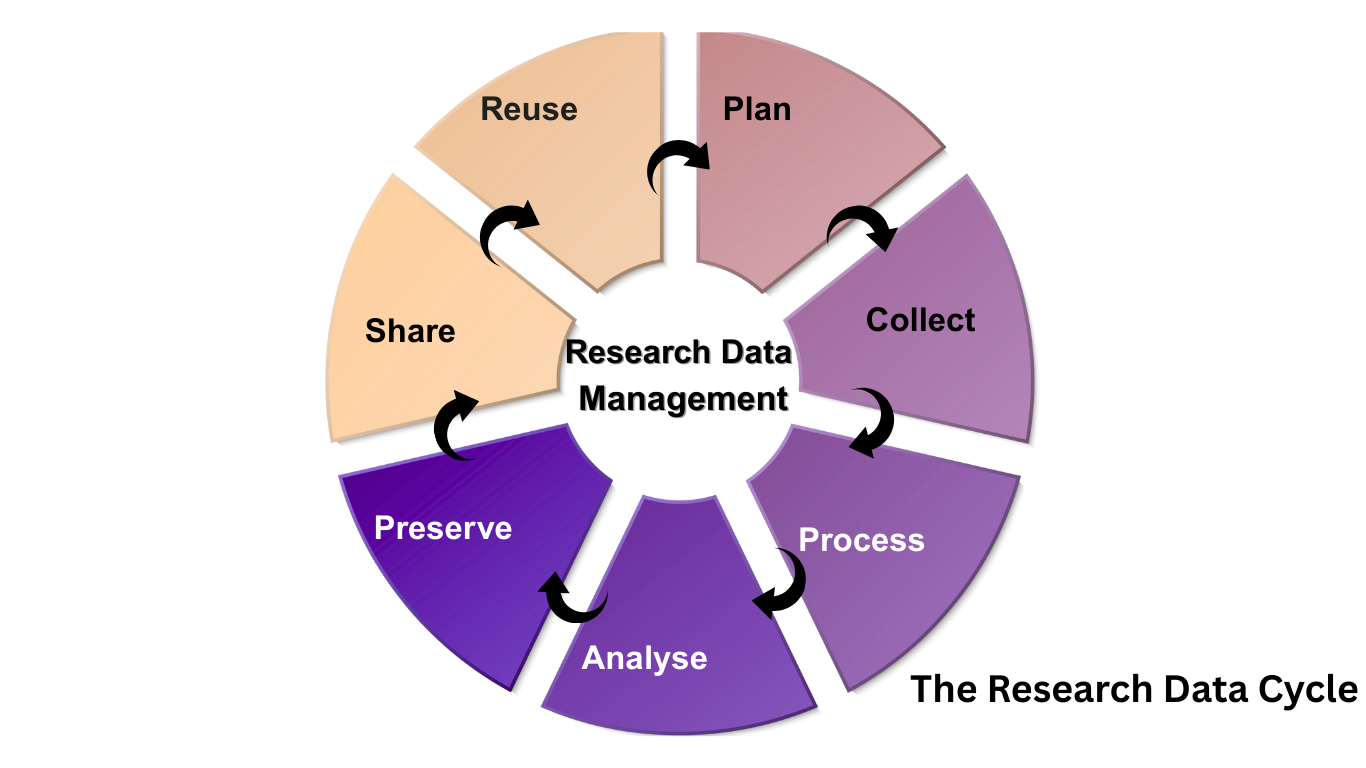
What is Research Data Management?
it's the management of your research data, throughout the research cycle including it's collection, organisation, analysis, sharing and preservation.
Benefits
Effective RDM ensures your research data is findable, accessible, interoperable, and reusable (FAIR). It supports research integrity, reproducibility, and maximises the impact of your work.
Good data management practices help you:
- Meet funder and publisher requirements
- Protect your research and prevent data loss
- Enable collaboration and data sharing
- Support reproducibility and research integrity
- Increase citations and research impact
- Comply with legal and ethical obligations
Why RDM Matters
Research funders, institutions, and publishers increasingly require researchers to manage and share their data responsibly. The Irish National Action Plan for Open Research (2022-2030) commits Ireland to making publicly funded research outputs, including data, openly available.
MTU supports researchers in meeting these requirements while maintaining best practices in data stewardship.
For more in-depth information on the fundamentals of open science and open research, please visit MTU’s Open Education Resource (OER), “Foundations of Open Science” on Canvas.
