MTU Research Data Management Policy 2025
FAIR principles allow findings to be verified, reproduced and digitally preserved; and therefore, are fundamental to high quality research outputs and research integrity. FAIR is the recognised standard for research data. MTU, research bodies and most funders require you to show how you will achieve this in a data management plan (DMP) for your project.
They are explained by the Open Science Training Handbook1 as follows:
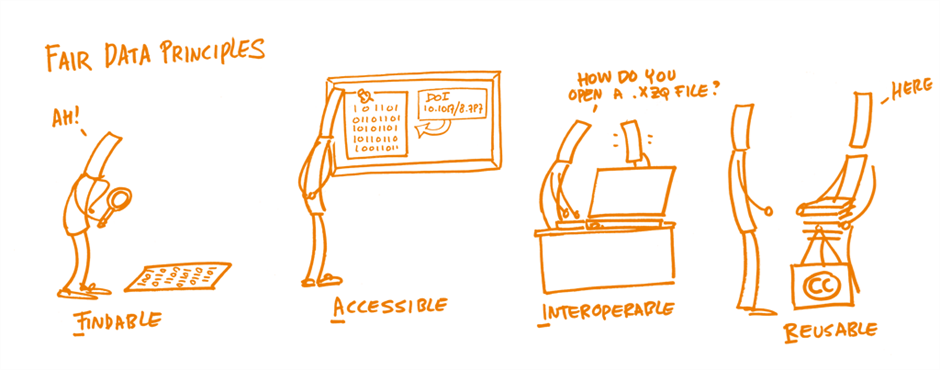
Put simply, it should be easy to find the data and the metadata (this is data which describes your dataset or the product of your research) from search engines.
The reliable discovery of datasets and metadata depends on well written metadata and if possible, and you should assign a persistent identifier (PID). PID's are long-lasting references to research and research data and can be assigned on websites such as Zenodo (for example: https://zenodo.org/records/7304703).
The metadata should be retrievable by their identifier using a standardized and open communications protocol. This means that retrieving the data should not require specialist tools, or licences for software. If possible, the metadata should include authentication and authorisation, or for sensitive data it should include contact information for the person who can provide access. Also, it should be explained that the attendant metadata will be available even when the data is no longer “live” on a website, or available to download.
The data should be able to be combined with and used with other data or tools. This means that the data should be open and interpretable for various tools (for example in a widely used format such as .jpeg, .csv, .html). The data should be described in a way that includes commonly used vocabularies (by using your discipline's usual naming conventions, subject headings, or thesauri). This description should apply both at the data and metadata level.
Ultimately, FAIR aims at optimizing the reuse of data. To achieve this, metadata and data should be well described so that they can be replicated and/or combined in different settings. Also, the reuse of the (meta)data should be stated with (a) clear and accessible license(s). For more information about copyright licensing, see the "Copyright Licensing" section.
Tip: The quickest and easiest way to ensure our research data is FAIR is by uploading well managed research data to a recognised data repository e.g. Zenodo.org. This will provide persistent links, called PID's (or DOI's), along with recognised metadata, language standards and licensing best suited to the data.
